
Η αλήθεια για το «Σκόιλ Ελικίκου» και η παραισθητική «ποίηση» των αλγορίθμων
Η αλήθεια για το «Σκόιλ Ελικίκου» και η παραισθητική «ποίηση» των αλγορίθμων

Μεταφορά από το Κοσμοδρόμιο, όπου είχε δημοσιευθεί το άρθρο στις 11 Απριλίου του 2021 και έχει χαθεί λόγω βλάβης στη βάση δεδομένων της έκδοσης

Χρήστο ΑΜΚΑ τι ζητάς; Εδώ δεν είναι παίξε γέλασε. Εδώ είναι Μπαλκάνια – Nίκος ڪاميابονόπουλος
Μια νέα βερσιόν του φαινομένου «σκόιλ ελικίκου» εμφανίστηκε προχθές στην πλατφόρμα των φαρμακοποιών για τα αυτοτέστ κορονοϊού. Τα Μέσα Κοινωνικής Δικτύωσης πλημμύρισαν από screenshots με μεγαλειώδεις μη-μεταφράσεις.

Το φαινόμενο ήταν στην περίπτωση αυτή περιστασιακό. Υπάρχουν μαρτυρίες φαρμακοποιών πως τους εμφανίστηκαν αυτά τα αλαμπουρνέζικα στην πλατφόρμα, αλλά δεν συνάντησαν όλοι, και μάλλον ούτε οι περισσότεροι, φαρμακοποιοί το ίδιο πρόβλημα. Η εξήγηση, που κυκλοφόρησε από τα φιλοκυβερνητικά ΜΜΕ (π.χ. εδώ στα ΝΕΑ), ήταν πως πρόκειται για παράγωγο της μετάφρασης google, η οποία κατασκευάστηκε μάλλον και σκοπίμως διέρρευσε ως “fake news”, από τα “τρολ” του “συστήματος ΣΥΡΙΖΑ”: μυθολογικό ον στο οποίο αποδίδονται κάθε είδους αντικυβερνητικές αποκαλύψεις και χιουμοριστικά μιμίδια από το ευρύ φιλοκυβερνητικό στρατόπεδο. Η εκδοχή αυτή κατέληξε και σε Δελτίο Τύπου.
Το δεύτερο σκέλος της ερμηνείας περί πηγής και (αρχικής τουλάχιστον) πρόθεσης είναι εσφαλμένο – όντως υπήρχαν φαρμακοποιοί οι οποίοι είδαν τα γκουκλοαλαμπουρνέζικα. Οι πρώτες αναφορές στο twitter, από όσο μπόρεσα και είδα ήταν από ανώνυμους μεν αλλά φαρμακοποιούς δε:





Αλλά ως προς το πρώτο σκέλος του ισχυρισμού πράγματι είναι βέβαιο πως πρόκειται για μεταφράσεις της google, ένα bug της μεθοδολογίας του Google Translate στην οποία θα επανέλθουμε παρακάτω. Τι έχει συμβεί; Κατά πάσα πιθανότητα όσοι έχουν τους φυλλομετρητές (browser) τους, ρυθμισμένους ώστε να μεταφράζουν σελίδες αυτόματα στα Ελληνικά, βρέθηκαν μπροστά σε αυτές τις μαγικές μεταφράσεις. Το Google Translate παθαίνει ένα ψυχεδελικό κοκομπλόκο σε περιπτώσεις τις οποίες δεν έχει “εκπαιδευτεί” να μεταφράζει – και η απαίτηση να μεταφράσει στα ελληνικά ως αγγλικό ένα κείμενο που είναι γραμμένο σε ελληνικά με ελληνικούς χαρακτήρες, πυροδοτεί αυτό το ψευδολυσεργικό ταξίδι στη μηχανική, ούτως ειπείν, “επινοητικότητα”. Οι περισσότεροι χρήστες που δεν είχαν ρυθμίσει, ακουσίως ή ακουσίως ανάλογα τον browser τους μάλλον δεν είχαν τέτοιο θέμα, αν και μου μεταφέρθηκαν επώνυμες μαρτυρίες πως ακόμα και φαρμακοποιοί που από όσο ξέρουν δεν είχαν ενεργοποιήσει αυτόματη μετάφραση στον browser έβλεπαν την προβληματική “μετάφραση”. Η ακριβής διερεύνηση της εμφάνισης ή μη των “ακαταλαβίστικων” θέλει περαιτέρω αναζήτηση και δεν μπορεί να γίνει χωρίς την καταγραφή των σχετικών ρυθμίσεων των υπολογιστών των χρηστών. Ξέρουμε πως για την αναγνώριση της γλώσσας μιας σελίδας, το google παρακάμπτει τη δηλωμένη στο html γλώσσα (καλύτερα: οι μισές σελίδες του δημοσίου τουλάχιστον που έχω μια εικόνα έχουν είτε λάθος γλώσσα δηλωμένη στο html τους -αγγλικά- είτε δεν έχουν καθόλου, όπως είναι η περίπτωση των εφαρμογών – αλλά όχι του σάιτ – της ΗΔΙΚΑ) και την αναγνωρίζει με βάση τα συμφραζόμενα. Ξέρουμε επίσης πως το google, όχι πολύ συχνά αλλά όχι και σπάνια, προτείνει εσφαλμένα τη μετάφραση και σελίδων που είναι στην ιθαγενή γλώσσα του λογαριασμού του χρήστη, ή που περιέχουν ένα μικρό μόνο μέρος του περιεχομένου τους σε άλλη γλώσσα. Οπότε πιθανολογώ πως υπό κάποιες συνθήκες όλο αυτό το κάζο ενδέχεται να οφείλεται σε δυσλειτουργία των ρυθμίσεων γλώσσας στο google / chrome.
Από εκεί και πέρα, με δεδομένο πως δεν υπήρχε γενική ή έστω μαζική πρόσβαση στην εφαρμογή, παρά μόνο από τους φαρμακοποιούς, οι εικόνες που οι πρώτοι καταγγέλλοντες φαρμακοποιοί ανάρτησαν, θεωρήθηκαν από πολλούς πανομοιότυπη περίπτωση “σκόιλ-ελικίκου” και οδήγησαν σε αυτό το “πάρτυ” στα ΜΚΔ από περίπου κάθε λογαριασμό του οποίου το στερεότυπο ανικανότητας της κυβέρνησης αυτής επιβεβαίωνε. Το αν υπάρχει κάποια αστοχία στην εγκατάσταση της εφαρμογής ή στην εφαρμογή την ίδια δεν μπορούμε να το πούμε με βεβαιότητα.
Η πιθανότητα η μετάφραση της εφαρμογής να έγινε επί τούτου ώστε να δημοσιοποιηθεί για λόγους αντιπολιτευτικούς, σκοντάφτει σε μαρτυρίες απλών φαρμακοποιών που δεν υπάρχει λόγος να μην γίνουν πιστευτές.
Για το μόνο για το οποίο είμαστε βέβαιοι λοιπόν είναι πως πρόκειται για “έργο Google”. Πώς το ξέρουμε; Δείτε την παρακάτω μετάφραση του σωστού κειμένου όπως τη δίνει online το Google translate:
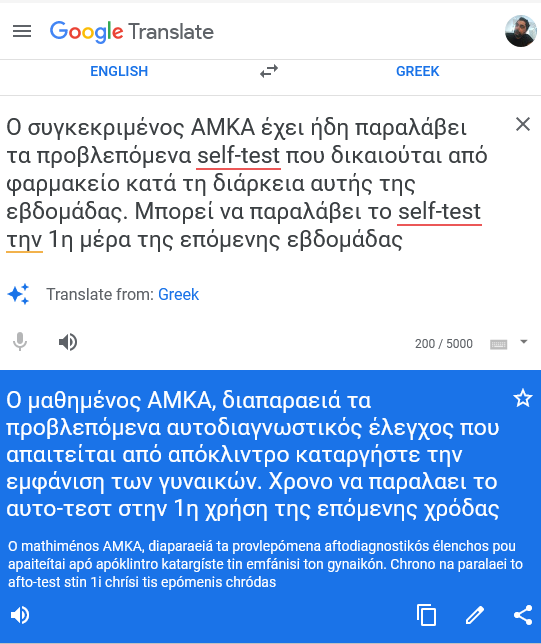
Όλα είναι εδώ: η χρόδα, το παραλάει, το απόκλιντρο. Δεν υπάρχει καμία αμφιβολία πως αυτός ο δαίμων του διαδικτύου είναι παιδί της Google.
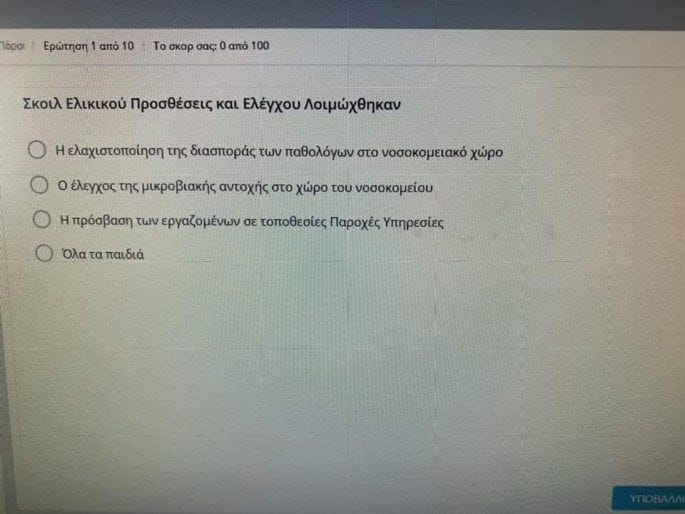
Και πάλι βέβαια αναρωτιέται κανείς γιατί αυτό δεν συμβαίνει συχνά και σε άλλες εφαρμογές, γιατί συνέβη μόνο σε αυτή την πλατφόρμα; Αλλά υπάρχει η πιθανότητα να συμβαίνει κάτι παρόμοιο και με άλλες εφαρμογές απλά να μη δημοσιοποιείται. Ένα προσωπικό πείραμα στο “ανάμεικτο” γλωσσικά timeline μου στο facebook, αλλάζοντας τις ρυθμίσεις γλώσσας, μου έδειξε πως κάποιες φορές προκύπτει πρόταση από το chrome για τη μετάφραση της σελίδας μου σε Ελληνικά από τα Αγγλικά. Σε αυτή την περίπτωση όντως οι Ελληνικές αναρτήσεις στο timeline μου μετατρέπονται μερικώς σε ακαταλαβίστικα. Χωρίς πρόσβαση στον κώδικα και κάποιου είδους καταγραφή σχετικών περιστατικών με τις πλατφόρμες δημόσιες ή ιδιωτικές δεν μπορεί να είμαστε σίγουροι για την αιτία της έξαρσης του “τενεκένα” και του Χρήστου ΑΜΚΑ. Δεν είναι όμως μοναδική περίπτωση: Όπως μου υπέδειξε η κ. Κατερίνα Γιανναράκη, εκπαιδευτικός, το πρόγραμμα kahoot, ένα εκπαιδευτικό παιχνίδι – εργαλείο βγάζει ανάλογα ακαταλαβίστικα στους μαθητές της. Ενδεικτικά:


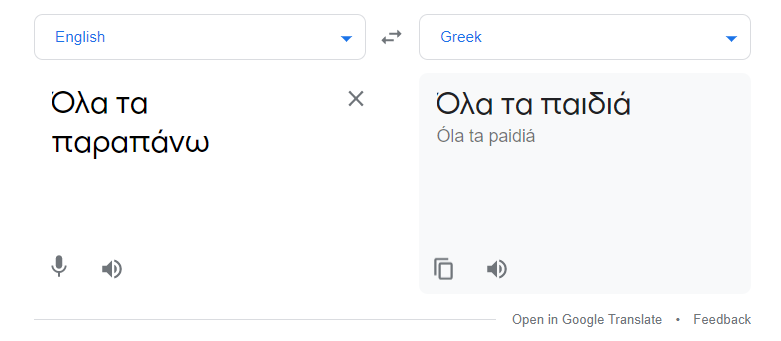
Στη δεύτερη εικόνα βλέπουμε μια γνώριμή μας φράση από το αρχικό έπος του “Σκόιλ Ελικίκου”: “Όλα τα παιδιά”
Τι είναι αυτό το “Όλα τα παιδιά”; Όπως βλέπουμε δεν είναι παρά η “μετάφραση” από ελληνικά (επισημανθέντα ως αγγλικά) σε ελληνικά της φράσης “όλα τα παραπάνω”
Σκόιλ Ελικίκου: μια ανάλυση
Αρχικά όταν είχε ξεσπάσει το σκάνδαλο με τις πλατφόρμες επιμόρφωσης των ελευθέρων επαγγελματιών, τις ακατάληπτες φράσεις και λέξεις τους, είχα υποθέσει πως επρόκειτο για κάποιου είδους σφάλμα OCR, οπτικής αναγνώρισης δηλαδή σκαναρισμένων κειμένων που τροφοδότησαν κακήν κακώς τις πλατφόρμες. Μου φαινόταν απίθανο το Google Translate το οποίο εντυπωσιάζει με τη σχετικά στρωτή του απόδοση όλων των γλωσσών συνήθως, να είχε παραγάγει τέτοιου είδους ηλεκτρονικά “μεταφραστικά σκουπίδια”. Είχα κάνει λάθος. Πρόκειται για σφάλμα στο λογισμικό της μετάφρασης της Google που υφίσταται κανονικότατα και σήμερα – και είναι προσβάσιμο με μια απλή επίσκεψη στο Google translate, online. Μερικά παραδείγματα:

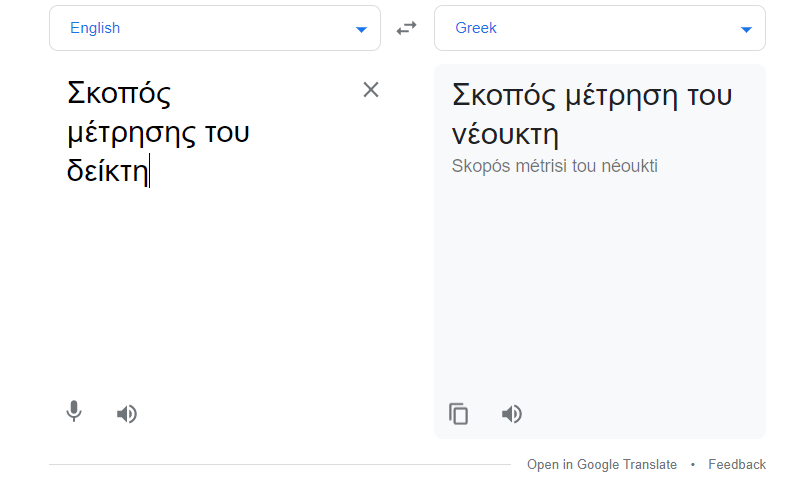
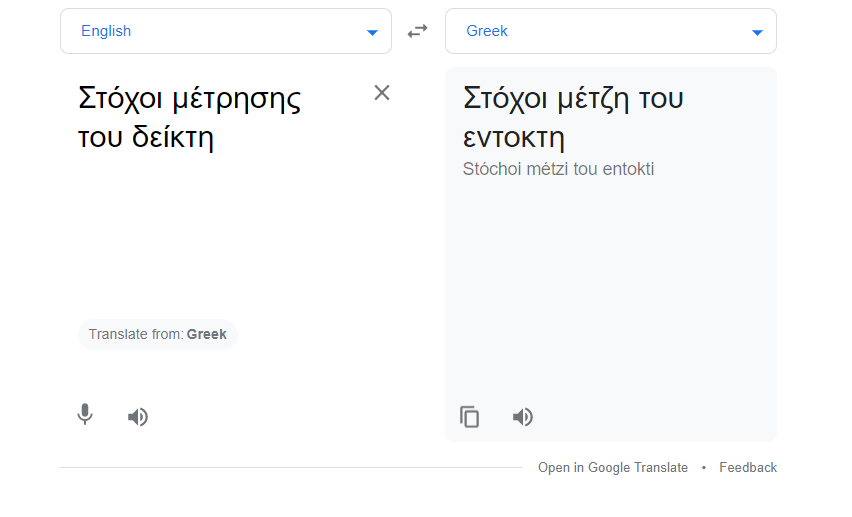
Σε αυτά τα μεταφραστικά δείγματα βρίσκουμε τους γνωστούς μας Μέτζη του νεούκτη, το Ελικίκου σχεδόν, αλλά χωρίς το Σκόιλ, το οποίο δεν κατόρθωσαν να βρω από τι παράγεται, κτλ.
Υπάρχει όμως εδώ μια διαφορά με τα πρόσφατα: οι χρήστες που είδαν τις γκουκλοαλαμπουρνέζικες λέξεις δεν ήταν μεμονωμένοι. Οι αναφορές ήταν καθολικές. Οι περισσότεροι από τους χρήστες, σύμφωνα με τα ρεπορτάζ εκείνων των ημερών, έπεσαν πάνω σε παρόμοιες αστειότητες.
Εικάζει κανείς πως έχει συμβεί το εξής: κάποιοι από τους δημιουργούς ή/και συνεργάτες αυτών των κατά κανόνα (σύμφωνα πάλι με τα όσα είχαν δει το φως της δημοσιότητας) εξαιρετικά προχειροφτιαγμένων και πεπαλαιωμένων σεμιναρίων στα πλαίσια του προγράμματος voucher για τους επιστήμονες, πέρασαν για κάποιον λόγο μαζικά τα ηλεκτρονικά τους κείμενα από Google Translate (Αγγλικά -> Ελληνικά) και τα ανάρτησαν χωρίς κανέναν ανθρώπινο έλεγχο στην πλατφόρμα τους. Αυτό είναι προφανώς μείζονος τάξης θέμα γιατί πρόκειται για παραδοτέο το οποίο χρυσοπληρώθηκε από Ελληνικό δημόσιο, και το οποίο, ακόμα και χωρίς τα μεταφραστικά αυτά παρατράγουδα, ήταν κατά μέσο όρο ευτελούς ποιότητας.
Εντύπωση όμως θα έπρεπε να προκαλεί και το ότι ακόμα εικάζουμε για την αιτία της αστειότητας αυτής. Από τη στιγμή που ξέσπασε όλος αυτός ο θόρυβος και η γελοιοποίηση θα περίμενε κανείς πως έναν χρόνο μετά θα είχαμε μια έκθεση του τι πήγε στραβά, πώς θα αποφευχθεί μελλοντικά, μαζί με μια ανάλυση, μην πω και αξιολόγηση, των παραδοθέντων. Τίποτα από αυτά δεν υπάρχει. Κατά πάσα πιθανότητα και στο ίδιο το Υπουργείο Εργασίας δεν γνωρίζουν τα παραπάνω. Ακόμα και στο επίκαιρο θέμα με την πλατφόρμα για τα τεστ για το SARS-CoV-19, αντί να βγει κάποιος σχετικός και να ερευνήσει την καταγγελία, να εντοπίσει την πηγή της και να εκδώσει οδηγίες για να μην παρουσιάζονται οι μεταφραστικές ανωμαλίες, η κυβέρνηση προτιμά να αποδίδει όλες τις δυσλειτουργίες σε θεωρίες συνωμοσίας (δεν βοήθησε πάντως που η αντιπολίτευση έσπευσε να καταγγείλει τη δυσλειτουργία αυτή, πριν καν γίνει γνωστή η έκταση και η αιτία της, βασισμένη στον χαβαλέ του twitter)…
Αν όμως όλο αυτό το Σκοιλ Ελικικου που μας βρίσκει πλέον σε τακτά χρονικά διαστήματα προέρχεται από τον αυτόματη μετάφραση του Google (που όπως είπαμε υπό κανονικές συνθήκες αποδίδει εντυπωσιακά καλά), γεννάται το ερώτημα, γιατί και πώς παθαίνει τέτοιο κάζο ολόκληρο Google Translate…
Νευρωνικές μεταφράσεις των αισθήσεων και των παραισθήσεων
Δεν είναι γνωστό γιατί ακριβώς συμβαίνει αυτό το μεταφραστικό παραλήρημα, αλλά παρόμοια φαινόμενα έχουν καταγραφεί και έχουν περιγραφεί ως “Παραισθήσεις της Νευρωνικής Μηχανικής Μετάφρασης” (Halucinations in Neural Machine Translations).
Το Google Translate δεν λειτουργεί όπως ένας τυπικός μεταφραστής. Δεν “ξέρει” τους κανόνες μιας γλώσσας, δεν “κτίζει” λεξιλόγιο και δεν αντιστοιχεί σημασίες σε επίπεδα λέξεων. Επεξεργάζεται στατιστικά τεράστιους όγκους κειμένων και μεταφράσεων, συνήθως από επίσημα έγγραφα ή από διαθέσιμες μεταφράσεις και έτσι συνθέτει πιο “ολιστικές”, ας πούμε, αποδόσεις. Από το 2016 και μετά το GT χρησιμοποιεί τεχνικές “βαθιάς μάθησης” και κτίζεται γύρω από ένα νευρωνικό δίκτυο, για το οποίο μπορείτε να διαβάσετε εδώ, αλλά η ακριβής του περιγραφή ξεπερνά τις φιλοδοξίες αυτού του άρθρου.
Μια βιαστική αναζήτηση στο διαδίκτυο, δείχνει πως – με κάθε επιφύλαξη – το είδος του προβλήματος της εισαγωγής ελληνικών ως αγγλικών και των μεταφραστικών παροξυσμών που προκαλούνται από την προσπάθεια απόδοσής τους, δεν έχει καταγραφεί έως τώρα ως περιστατικό με κάποια δημόσια αναφορά. Αντίθετα, έχουν αναδειχθεί περιπτώσεις όπου “τυχαίες” είσοδοι προς μετάφραση σε ορισμένες γλώσσες δίνουν απρόσμενα αποτελέσματα. Εδώ το Language Log είχε ασχοληθεί εκτενώς με τις περιπέτειες της μετάφρασης από τα Χαβανέζικα, τα οποία (ίσως λόγω πηγών που ήταν οι περισσότερες βιβλικές ή θρησκευτικές) μεταφράζουν και τις πιο απλές ασυναρτησίες σε ποιητικές εξάρσεις:
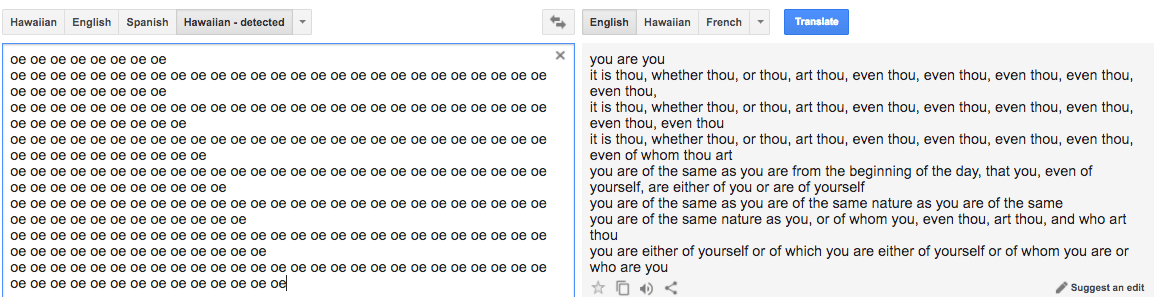
Δοκίμασα λοιπόν κάτι παρόμοιο με input τα όσα παρήγαγαν το “νεούκτη” από τα αγγλικά, αλλά ορίζοντας σαν αρχική γλώσσα του υπό μετάφραση κειμένου τα “Χαβαϊκά”, λαμβάνοντας υπόψη πως στις “μεταφράσεις” αυτές της Google, μικρή αλλαγή στο κείμενο που εισάγεται προς μετάφραση (ένα κόμμα, ένα κεφαλαίο) μπορεί να αλλάξει δραστικά το αποτέλεσμα της μετάφρασης. Ο “Νίκος Εγγονόπουλος” που (περίπου) παραθέσαμε στην αρχή του άρθρου, αποδίδεται “Νίκος Εγγονόπουλος” αν εισαχθεί ως αγγλική λέξη προς μετάφραση, αλλά αν εισάγει κανείς τις λέξεις “νίκος εγγονόπουλος” (με όλα πεζά) το αποτέλεσμα είναι το ημιαραβικό υβρίδιο που βλέπετε επάνω. Το ποιητικό προϊόν αυτής της άσκησης χρησιμοποιώντας την ίδια φράση με προσθήκες σημείων στίξης, και αλλαγής κεφαλαίων πεζών είναι το ακόλουθο:

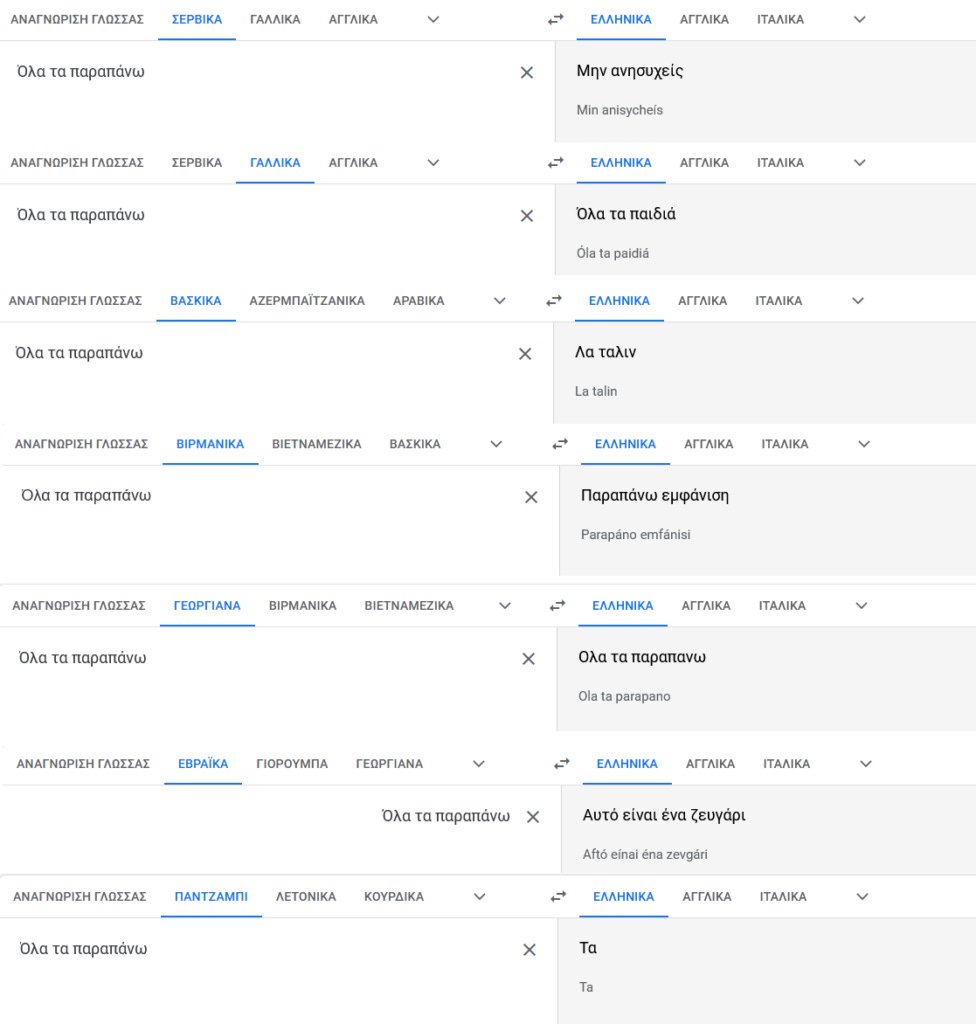
Τέλος ένα ακόμα “πείραμα” δείχνει πως η μετάφραση “Όλα τα παιδιά” για το “Όλα τα παραπάνω” δεν έχει μονοσήμαντη σχέση με την γλώσσα εισαγωγής. Εισαγόμενο στις περισσότερες γλώσσες το “Όλα τα παραπάνω” παράγει ως μετάφραση το “Όλα τα παιδιά”, σε ελάχιστες το αφήνει ως έχει και από εκεί και πέρα τα αποτελέσματα ποικίλουν….
Επίμετρο: τα όνειρα των νευρωνικών δικτύων
Πέρα από τη μετάφραση η Google χρησιμοποιεί νευρωνικά δίκτυα και για την αναγνώριση εικόνων. Το πρόγραμμα DeepDream παρουσιάζει τις εικόνες όπως τις επεξεργάζεται ένα νευρωνικό δίκτυο. Ως εικονογράφηση αυτού του άρθρου λοιπόν επιλέξαμε την εικόνα του ακουσίως εισαγάγοντα τις νευρωνικές δικτυακές παραισθήσεις της Google στη δημόσια επικαιρότητα, Γιάννη Βρούτση περασμένο από τους αλγορίθμους αυτούς…